NIL: No-data Imitation Learning by Leveraging Pre-trained Video Diffusion Models
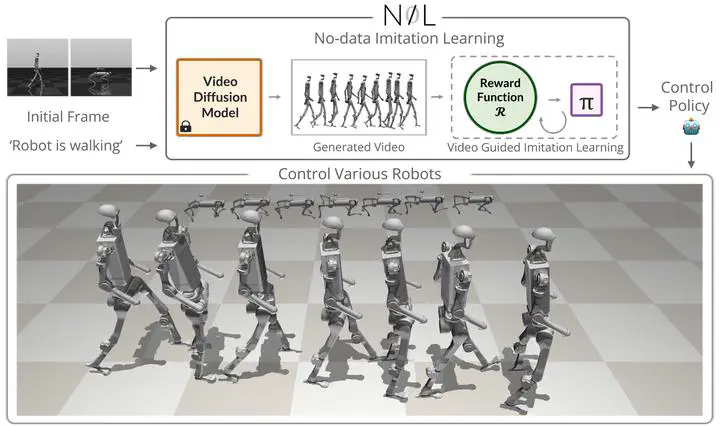 NIL Overview: from single frame + prompt → generated video → policy learning.
NIL Overview: from single frame + prompt → generated video → policy learning.Type
Publication
In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2026
Abstract
Acquiring physically plausible motor skills across diverse and unconventional morphologies—from humanoids to ants—is crucial for robotics and simulation. We introduce No-data Imitation Learning (NIL), which:
- Generates a reference video with a pretrained video diffusion model from a single simulation frame + text prompt.
- Learns a policy in simulation by comparing rendered agent videos against the generated reference via video-encoder embeddings and segmentation-mask IoU.
NIL matches or outperforms baselines trained on real motion-capture data, effectively replacing expensive data collection with generative video priors.
NIL Overview

Stage 1: Generate reference video F with diffusion model D from initial frame and text prompt.
Stage 2: Train policy in physics simulator to imitate the generated video using (1) video-encoder similarity, (2) segmentation IoU, (3) smoothness regularization.
Stage 2: Train policy in physics simulator to imitate the generated video using (1) video-encoder similarity, (2) segmentation IoU, (3) smoothness regularization.
Experiments
We validate NIL on locomotion tasks for multiple morphologies (humanoids, quadrupeds, animals).
- Reward components: ablation of video vs. mask vs. reg.
- Policy performance: matches or exceeds motion-capture-trained baselines.
- Generalization: works zero-shot on unseen morphologies.
BibTeX
@inproceedings{albaba2026nil,
title = {{NIL}: No-data Imitation Learning by Leveraging Pre-trained Video Diffusion Models},
author = {Albaba, Mert and Li, Chenhao and Diomataris, Markos and Taheri, Omid and Krause, Andreas and Black, Michael},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2026},
}
Omid Taheri
PostDoc Researcher | Open to Research Scientist Roles
Building Digital Humans that move, interact, and reason like Real Humans – bridging generative AI, vision-language models, and physics-based simulation.