Omid Taheri
PostDoc Researcher | Open to Research Scientist Roles
MPI for Intelligent Systems - Perceiving Systems
About Me
Hello!
I am wrapping up my postdoc at Michael Black’s group (MPI for Intelligent Systems), where I also completed my Ph.D. under the guidance of Professor Michael J. Black and Dr. Dimitrios Tzionas. I bring several years of deep expertise in Embodied AI, Digital Humans, 3D Vision, and more recently Generative AI, with a strong track record of connecting LLMs and VLMs to various structured physical tasks – from dexterous grasping and avatar motion to hand-object interaction, video understanding, and garment generation.
That bridge between the semantic knowledge of foundation models and structured 3D / physical tasks is where I do my best work.
I am currently on the job market, looking for Research Scientist or similar roles. If you are looking for someone motivated, with deep expertise in GenAI, diffusion models, LLM/VLM, digital humans, dexterous manipulation, avatar control, and video understanding – let us talk. Feel free to reach out!
- Digital Humans & Avatar Animation
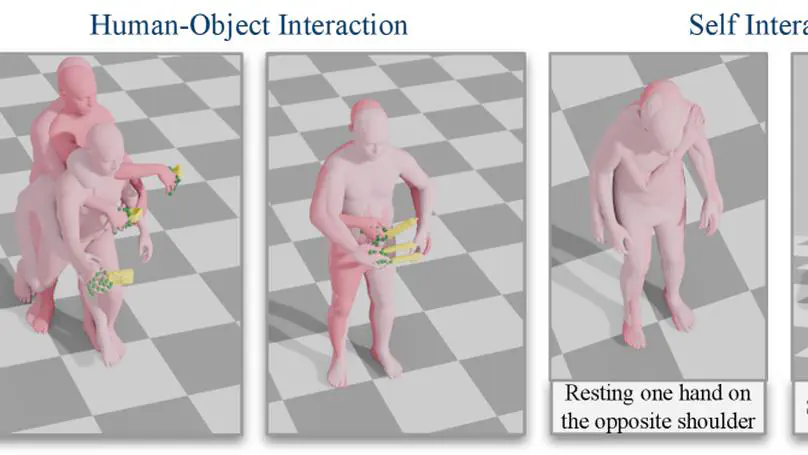
- Human-Object Interaction
- Diffusion Models for Motion & Video
- LLM/VLM for Avatar Control & Interaction
- Text-to-Motion Generation
- Grasp Synthesis & Manipulation
- Video Understanding
- 3D Reconstruction & Representation
- Embodied AI & Robotics
PostDoc Researcher - AI and Computer Vision, 2024-Present
Max Planck Institute for Intelligent Systems, Tuebingen, DE.
Ph.D. in Computer Science - AI and Computer Vision, 2018–2024
Max Planck Institute for Intelligent Systems, Tuebingen, DE.
M.Sc. in Mechanical Engineering - Applied Mechanics (Control and Robotics), 2014-2017
Sharif University of Technology, Tehran, IR.
B.Sc. in Mechanical Engineering - Mechatronics, 2010-2014
Isfahan University of Technology, Isfahan, IR.
Publications
For a complete and up-to-date list of publications, check out my Google Scholar.



Skills
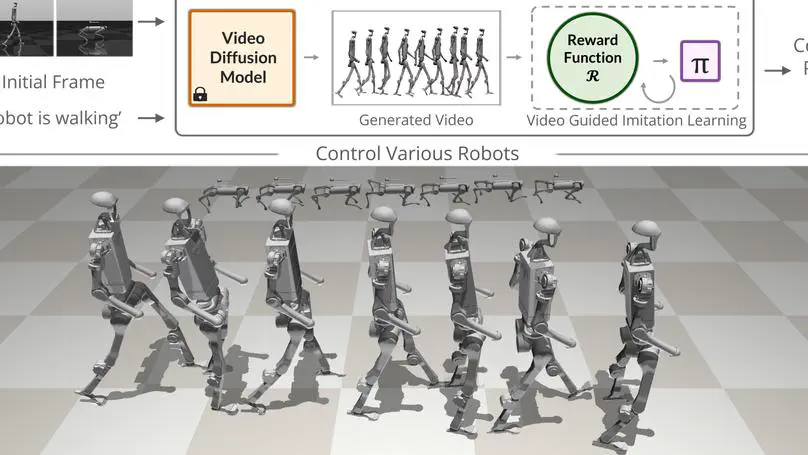
Motion, video, and 3D generation.
Language and vision models for avatar control and interaction.
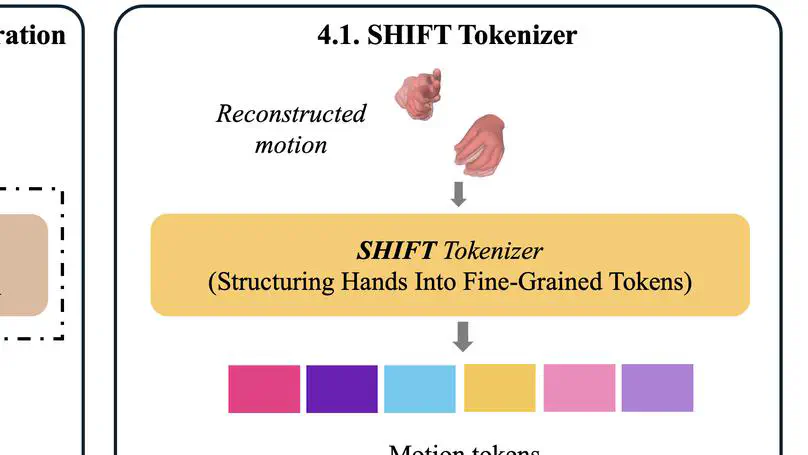
Text-to-motion, avatar animation, and body-hand generation.
Grasp synthesis, contact estimation, and whole-body interaction.
3D reconstruction, video understanding, and scene reasoning.
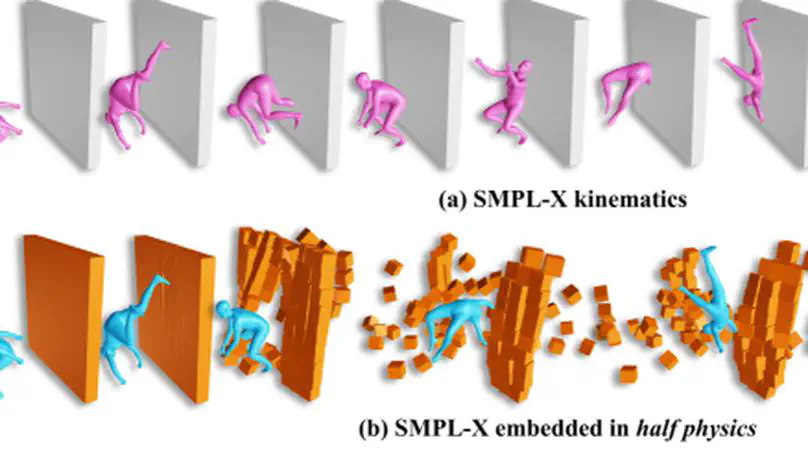
Physics-aware modeling and sim-to-real transfer.
Mesh, implicit, and parametric body models (SMPL-X, MANO).
PyTorch, transformers, and generative model architectures.
Research Experience
Collecting motion data with various systems including:
- Vicon MoCap System
- 3D Scanners
- RGB Cameras
- IMU Sensors
- Pressure Sensors
- Gaze Tracker
Awards & Honors
Contact
Access Map
- omid.taheri@tue.mpg.de
- Max-Planck-Ring 4, Tubingen, BW 72076
- PS Department, 3rd Floor
- Twitter (DMs open)