 Teaser
TeaserAbstract
Synthesizing natural human motions that enable a 3D human avatar to walk and reach for arbitrary goals in 3D space remains an unsolved problem with many applications. Existing methods (data-driven or using reinforcement learning) are limited in terms of generalization and motion naturalness. A primary obstacle is the scarcity of training data that combines locomotion with goal reaching.
To address this, we introduce WANDR, a data-driven model that takes an avatar’s initial pose and a goal’s 3D position and generates natural human motions that place the end effector (wrist) on the goal location. To solve this, we introduce novel intention features that drive rich goal-oriented movement.
Intention guides the agent to the goal, and interactively adapts the generation to novel situations without needing to define sub-goals or the entire motion path. Crucially, intention allows training on datasets that have goal-oriented motions as well as those that do not. WANDR is a conditional Variational Auto-Encoder (c-VAE), which we train using the AMASS and CIRCLE datasets. We evaluate our method extensively and demonstrate its ability to generate natural and long-term motions that reach 3D goals and generalize to unseen goal locations.
What is WANDR?
WANDR is a conditional Variational AutoEncoder (c-VAE) that generates realistic motion of human avatars that navigate towards an arbitrary goal location and reach for it.
Input: The initial pose of the avatar, the goal location, and the desired motion duration.
Output: A sequence of poses that guide the avatar from the initial pose to the goal location and place the wrist on it.
*Starting from the same state, WANDR generates diverse motions to reach different goal locations all around the human.*How is WANDR unique?
WANDR is the first human motion generation model driven by an active feedback loop learned purely from data, without any extra steps of reinforcement learning (RL).
Active closed loop guidance through intention features: WANDR generates motion autoregressively (frame-by-frame). At each step, it predicts a state-delta that will progress the human to the next state. The prediction of the state-delta is conditioned on time- and goal-dependent features that we call “intention” (visualized as arrows in videos below). These features are computed at every frame and act as a feedback loop that guides the motion generation to reach the goal. For more details on the intention, please refer to section 3.2 of the paper.
Purely data-driven training: Existing datasets that capture motion of humans reaching for goals, like CIRCLE, are scarce and have very small scale to enable generalization. This is why RL is a popular approach to learn similar tasks. However, RL comes with its own set of challenges such as sample complexity. Inspired by the paradigm of behavioral cloning we propose a purely data-driven approach where during training a future position of the avatar’s hand is considered as the goal. By hallucinating goals this way, we are able to combine both smaller datasets with goal annotations such as CIRCLE, as well as large scale like AMASS that have no goal labels but are essential to learning general navigational skills such as walking, turning etc.
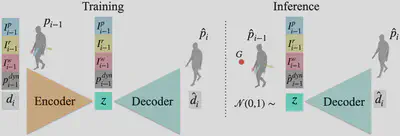
Method
Our method is based on a conditional Variational Auto-Encoder (c-VAE) that learns to model motion as a frame-by-frame generation process by auto-encoding the pose difference between two adjacent frames. The condition signal consists of the human’s current pose and dynamics along with the intention information. Intention is a function of both the current pose and the goal location and therefore actively guides the avatar during the motion generation in a closed loop manner. Through training, the c-VAE learns the distribution of potential subsequent poses conditioned on the current dynamic state of the human and its intention towards a specific goal.
We train WANDR using two datasets: AMASS, which captures a wide range of motions including locomotion, and CIRCLE, which captures reaching motions. During inference, intention features are calculated based on the goal and act as a feedback loop that guides the motion generation towards the goal.
Adapting to dynamic goals without training for it
Since WANDR generates motion autoregressively, the intention features are updated at every frame. This allows the model to adapt to goals that move and change over time. Observe in the videos below how the intention features actively guide the avatar to orient itself towards the goal (orange arrow), get close to it (red arrow) and reach for it (blue arrow).
WANDR generates motion autoregressively. This allows it to adapt to goals that move and change over time even though it has never been trained on scenarios with dynamic goals.
Video
Citation
@inproceedings{diomataris2024wandr,
title = {{WANDR}: Intention-guided Human Motion Generation},
author = {Diomataris, Markos and Athanasiou, Nikos and Taheri, Omid and Wang, Xi and Hilliges, Otmar and Black, Michael J.},
booktitle = {Proceedings IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2024},
}
Omid Taheri
PostDoc Researcher | Open to Research Scientist Roles
Building Digital Humans that move, interact, and reason like Real Humans – bridging generative AI, vision-language models, and physics-based simulation.