GRIP: Generating Interaction Poses Using Spatial Cues and Latent Consistency
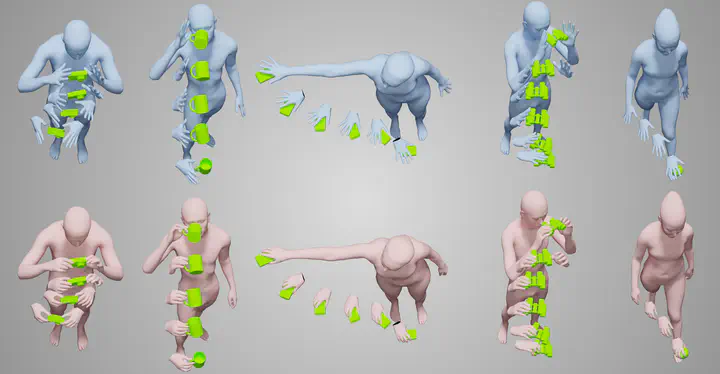 Teaser
TeaserAbstract
Hands are dexterous and highly versatile manipulators that are central to how humans interact with objects and their environment. Consequently, modeling realistic hand-object interactions, including the subtle motion of individual fingers, is critical for applications in computer graphics, computer vision, and mixed reality. Prior work on capturing and modeling humans interacting with objects in 3D focuses on the body and object motion, often ignoring hand pose. In contrast, we introduce GRIP, a learning-based method that takes, as input, the 3D motion of the body and the object, and synthesizes realistic motion for both hands before, during, and after object interaction. As a preliminary step before synthesizing the hand motion, we first use a network, ANet, to denoise the arm motion. Then, we leverage the spatio-temporal relationship between the body and the object to extract novel temporal interaction cues, and use them in a two-stage inference pipeline to generate the hand motion. In the first stage, we introduce a new approach to encourage motion temporal consistency in the latent space (LTC) and generate consistent interaction motions. In the second stage, GRIP generates refined hand poses to avoid hand-object penetrations. Given sequences of noisy body and object motion, GRIP “upgrades” them to include hand-object interaction. Quantitative experiments and perceptual studies demonstrate that GRIP outperforms baseline methods and generalizes to unseen objects and motions from different motion-capture datasets. Our models and code are available for research purposes at GRIP.
Video
Data and Code
Please register and accept the License Agreement on this website to access the GRIP models. When creating an account, please opt-in for email communication, so that we can reach out to you via email to announce potential significant updates.
- Model files/weights (works only after sign-in)
- Code (GitHub)
Results
Citation
@inproceedings{taheri2024grip,
title = {{GRIP}: Generating Interaction Poses Using Latent Consistency and Spatial Cues},
author = {Omid Taheri and Yi Zhou and Dimitrios Tzionas and Yang Zhou and Duygu Ceylan and Soren Pirk and Michael J. Black},
booktitle = {International Conference on 3D Vision ({3DV})},
year = {2024},
url = {https://grip.is.tue.mpg.de}
}
Omid Taheri
PostDoc Researcher | Open to Research Scientist Roles
Building Digital Humans that move, interact, and reason like Real Humans – bridging generative AI, vision-language models, and physics-based simulation.