GRAB: A Dataset of Whole-Body Human Grasping of Objects
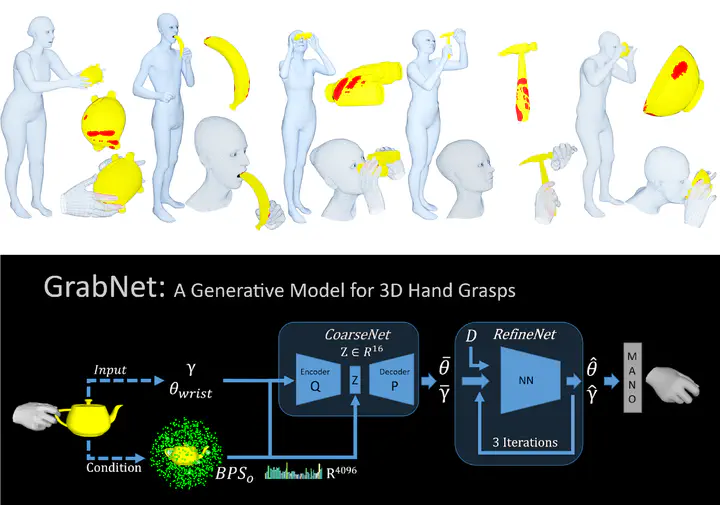 Teaser
TeaserAbstract
Training computers to understand, model, and synthesize human grasping requires a rich dataset containing complex 3D object shapes, detailed contact information, hand pose and shape, and the 3D body motion over time. While “grasping” is commonly thought of as a single hand stably lifting an object, we capture the motion of the entire body and adopt the generalized notion of “whole-body grasps”. Thus, we collect a new dataset, called GRAB (GRasping Actions with Bodies), of whole-body grasps, containing full 3D shape and pose sequences of 10 subjects interacting with 51 everyday objects of varying shape and size. Given MoCap markers, we fit the full 3D body shape and pose, including the articulated face and hands, as well as the 3D object pose. This gives detailed 3D meshes over time, from which we compute contact between the body and object. This is a unique dataset, that goes well beyond existing ones for modeling and understanding how humans grasp and manipulate objects, how their full body is involved, and how interaction varies with the task. We illustrate the practical value of GRAB with an example application; we train GrabNet, a conditional generative network, to predict 3D hand grasps for unseen 3D object shapes.
TL;DR
We capture a very accurate dataset, named GRAB, of people interacting with 3D objects. We then use it to train a network, GrabNet, that generates hand grasps for novel objects.
GRAB Dataset
Dataset Overview
GRAB is a dataset of full-body motions interacting and grasping 3D objects. It contains accurate finger and facial motions as well as the contact between the objects and body. The dataset includes 5 male and 5 female participants performing 4 different motion intents with 51 everyday objects.
Example Motions
| Eat - Banana | Talk - Phone | Drink - Mug | See - Binoculars |
|---|---|---|---|
 |  |  |  |
The GRAB dataset also contains binary contact maps between the body and objects. With our interacting meshes, one could integrate these contact maps over time to create “contact heatmaps”, or even compute fine-grained contact annotations, as shown below:
| Contact Heatmaps | Contact Annotation |
|---|---|
 |  |
Dataset Videos
| Long Video | Short Video |
|---|---|
 |  |
GrabNet
Overview
GrabNet is a generative model for 3D hand grasps. Given a 3D object mesh, GrabNet can predict several hand grasps for it. GrabNet has two successive models, CoarseNet (cVAE) and RefineNet. It is trained on a subset (right hand and object only) of the GRAB dataset.
Generated Results from GrabNet
| Binoculars | Mug | Camera | Toothpaste |
|---|---|---|---|
 |  |  |  |
GrabNet Videos
| Long Video | Short Video |
|---|---|
| |
Data and Code
Please register and accept the License agreement on this website in order to get access to the GRAB dataset. The license and downloads section include explicit restrictions per subject, to which you agree to comply with.
When creating an account, please opt-in for email communication, so that we can reach out to you per email to announce potential significant updates.
- GRAB dataset (works only after sign-in)
- GrabNet data (works only after sign-in)
- GrabNet model files/weights (works only after sign-in)
- Code for GRAB (GitHub)
- Code for GrabNet (GitHub)
Citation
@inproceedings{GRAB:2020,
title = {{GRAB}: A Dataset of Whole-Body Human Grasping of Objects},
author = {Taheri, Omid and Ghorbani, Nima and Black, Michael J. and Tzionas, Dimitrios},
booktitle = {European Conference on Computer Vision (ECCV)},
year = {2020},
url = {https://grab.is.tue.mpg.de}
}
Omid Taheri
PostDoc Researcher | Open to Research Scientist Roles
Building Digital Humans that move, interact, and reason like Real Humans – bridging generative AI, vision-language models, and physics-based simulation.