 FUSION: Unified diffusion-based full-body motion prior
FUSION: Unified diffusion-based full-body motion priorAbstract
Hands are central to interacting with our surroundings and conveying gestures, making their inclusion essential for full-body motion synthesis. Yet existing methods either ignore hands entirely or operate under highly constrained conditions. We present FUSION, the first diffusion-based unconditional full-body motion prior that jointly models body and hand dynamics.
We create a unified dataset by combining heterogeneous hand motion sources (41K sequences from 7 datasets) with large-scale body motion data (145K sequences), and train a transformer-based diffusion model that captures coordinated full-body dynamics. FUSION surpasses state-of-the-art skeletal control models on the Keypoint Tracking task and demonstrates two novel applications: generating finger-level detail during object interaction, and creating self-interaction motions guided by natural language prompts via LLM-generated contact specifications.
Method Overview
Our approach operates on the SMPL-X representation, using canonicalized trajectory features (508 dimensions) across 120-frame sequences. The transformer-based diffusion model (19.7M parameters) is trained with three loss components:
- Reconstruction loss for pose accuracy
- Geometric loss ensuring forward kinematics consistency
- Foot skating loss preventing unnatural ground penetration
For downstream tasks, we use diffusion noise optimization – iteratively refining the latent space through gradient-based updates with task-specific constraints such as keypoint tracking and contact enforcement.
Applications
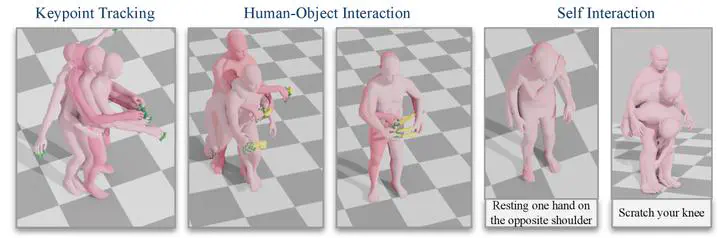
Keypoint Tracking
FUSION achieves competitive performance on HumanML3D with an average error of 1.78 cm while demonstrating superior motion realism (FID: 0.37 vs. -7.86 for TLControl) and reduced foot skating (6.03% vs. 13.80%).
Human-Object Interaction
By integrating static grasp predictions with full-body motion optimization, FUSION synthesizes realistic grasping and manipulation sequences with precise hand control while maintaining plausible full-body coordination.
Self-Interaction via LLMs
A novel pipeline converts natural language commands (e.g., “touch your head”) into structured contact constraints through LLM analysis of body vertices, achieving 0.897 average BERTScore F1 in semantic alignment validation.
Key Results
| Metric | FUSION | TLControl |
|---|---|---|
| Average Error (cm) | 1.78 | 1.57 |
| Motion Realism (FID) | 0.37 | -7.86 |
| Skating Ratio (%) | 6.03 | 13.80 |
Perceptual studies show that subjects preferred FUSION’s hand motion realism over baseline methods, with comparable performance to ground truth.
Dataset
- Body Motion: 145,100 sequences from AMASS, ARCTIC, OMOMO, SAMP, BEAT2
- Hand Motion: 41,148 sequences from 7 sources including InterHand2.6M, GRAB, ARCTIC
- Total: 17.4M timeframes at 30 FPS with penetration-based filtering
- Augmentation: Pose flipping and temporal reversal to enhance diversity
BibTeX
@article{duran2026fusion,
title = {{FUSION}: Full-Body Unified Motion Prior for Body and Hands via Diffusion},
author = {Duran, Enes and Athanasiou, Nikos and Kocabas, Muhammed and Black, Michael J. and Taheri, Omid},
journal = {arXiv preprint arXiv:2601.03959},
year = {2026},
}
Omid Taheri
PostDoc Researcher | Open to Research Scientist Roles
Building Digital Humans that move, interact, and reason like Real Humans – bridging generative AI, vision-language models, and physics-based simulation.