CLUTCH: Contextualized Language Model for Unlocking Text-Conditioned Hand Motion Modelling in the Wild
 CLUTCH: Text-conditioned hand motion generation in the wild
CLUTCH: Text-conditioned hand motion generation in the wildAbstract
Hands play a central role in daily life, yet modeling natural hand motions remains underexplored. Existing methods that tackle text-to-hand-motion generation or hand animation captioning rely on studio-captured datasets with limited actions and contexts, making them costly to scale to in-the-wild settings. Further, contemporary models and their training schemes struggle to capture animation fidelity with text-motion alignment.
To address this, we introduce 3D Hands in the Wild (3D-HIW), a dataset of 32K 3D hand-motion sequences with aligned text descriptions, and propose CLUTCH, an LLM-based hand animation system with two critical innovations: (1) SHIFT, a novel part-modality decomposed VQ-VAE architecture for improved hand motion tokenization, and (2) a geometric refinement stage that finetunes the LLM. CLUTCH establishes the first benchmark for scalable in-the-wild hand motion modelling, demonstrating strong results on bidirectional text-to-motion and motion-to-text tasks.
CLUTCH Overview
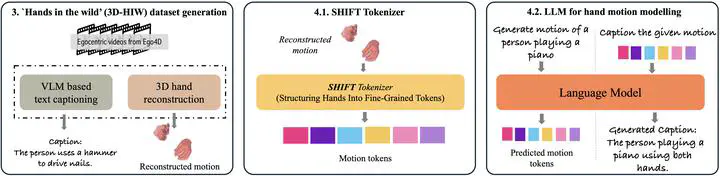
CLUTCH synthesizes and captions in-the-wild 3D hand motions through three key steps:
- In-the-wild data generation (3D-HIW): We integrate a state-of-the-art 3D hand tracker with a vision-language model applied to egocentric action videos, producing 32K hand-motion sequences with aligned text descriptions.
- SHIFT tokenizer: A part-modality decomposed VQ-VAE that separately encodes finger articulation and wrist motion, improving reconstruction fidelity and generalization.
- LLM-based motion modelling: We train an LLM to model both text and motion in a unified token space, enabling bidirectional text-to-motion and motion-to-text generation, followed by a geometric refinement stage with co-supervision on decoded hand parameters.
Key Contributions
- 3D-HIW Dataset: 32,000 in-the-wild 3D hand-motion sequences paired with natural language descriptions, significantly scaling beyond studio-captured datasets.
- SHIFT Tokenizer: Part-modality decomposed VQ-VAE that separately handles finger articulation and wrist dynamics, achieving superior reconstruction compared to standard VQ-VAE approaches.
- Geometric Refinement: A refinement stage that finetunes the LLM with reconstruction loss on decoded MANO hand parameters, improving animation fidelity.
- State-of-the-art results on both text-to-motion generation and motion-to-text captioning benchmarks.
BibTeX
@inproceedings{thambiraja2026clutch,
title = {{CLUTCH}: Contextualized Language Model for Unlocking Text-Conditioned Hand Motion Modelling in the Wild},
author = {Thambiraja, Balamurugan and Taheri, Omid and Danecek, Radek and Becherini, Giorgio and Pons-Moll, Gerard and Thies, Justus},
booktitle = {The Fourteenth International Conference on Learning Representations},
year = {2026},
url = {https://openreview.net/forum?id=W7YRskO47j}
}
Omid Taheri
PostDoc Researcher | Open to Research Scientist Roles
Building Digital Humans that move, interact, and reason like Real Humans – bridging generative AI, vision-language models, and physics-based simulation.